
人与车的关系,离不开「交互」两个字。无论是传统汽车时代的机械按键,还是智能汽车时代的触控屏幕、语音交互,寻找到更安全、高效、舒适的交互方式,一直是行业的共同追求;什么样的交互方式是更合适的,也是行业永恒探讨的命题。
在之前的橙皮书 《语音交互:浮躁转向务实,死磕体验价值》 中,我们探讨了语音交互在过去一年里的成长和未来的趋势。语音交互趋于务实的背后,是座舱系统逐渐去适应人、迎合人自然交互习惯的过程。不只是语音交互,以语音交互为基础的多模态交互能力,监测座舱内实时信息并给出应对的 DMS/OMS 功能,未来座舱与驾驶之间的融合联动,以及它们背后赋能的 AI 技术等等,这些能力各自提升的同时,也共同构成了座舱系统整体从被动交互向主动交互的转型。
在转向主动交互过程中,用户可以以更自然的方式与系统沟通,甚至更模糊的指令和意图能够被系统理解,系统也尝试根据用户和座舱内的状态提供更细致化的服务。
为了更好地印证我们的观察,这次我们与地平线智能交互团队聊了聊,来共同探讨一下座舱交互如何提供更细颗粒度的主动服务?
DMS/OMS:「麻烦制造机」的进化之路
如果说座舱内总有一些智能化配置被视作「炫技」的话,那 DMS/OMS 功能绝对是实用性功能的代表。
利用座舱内的摄像头,通过利用座舱内的摄像头追踪驾驶员瞥向指定屏幕的视线,随即自动亮屏或唤醒车载助手;通过 Face ID 实现账号登陆,驾驶员进入座舱后自动调节座椅位置角度;通过对驾驶员面部微表情和眼动的监测,在驾驶员分心或出现疲劳时,适时发出预警与提醒;利用摄像头识别抽烟、睡觉等情况,实现智能调解车窗状态,空气内外循环、降低音量等场景化服务。

高效、安全、舒适, 人们对于座舱内的三大基本需求,DMS/OMS 功能可以说都涵盖了。
前不久,高工智能汽车监测数据显示,2022 年前 11 个月乘用车 DMS 标配搭载 99.95 万辆,同比增长 111.8%;在 DMS 感知方案供应商方面,地平线(芯片+感知)、商汤、虹软排名市场份额前三位。有机构预测,到 2026 年 DMS 的渗透率将达到 35%,DMS/OMS 上车的趋势不可挡。
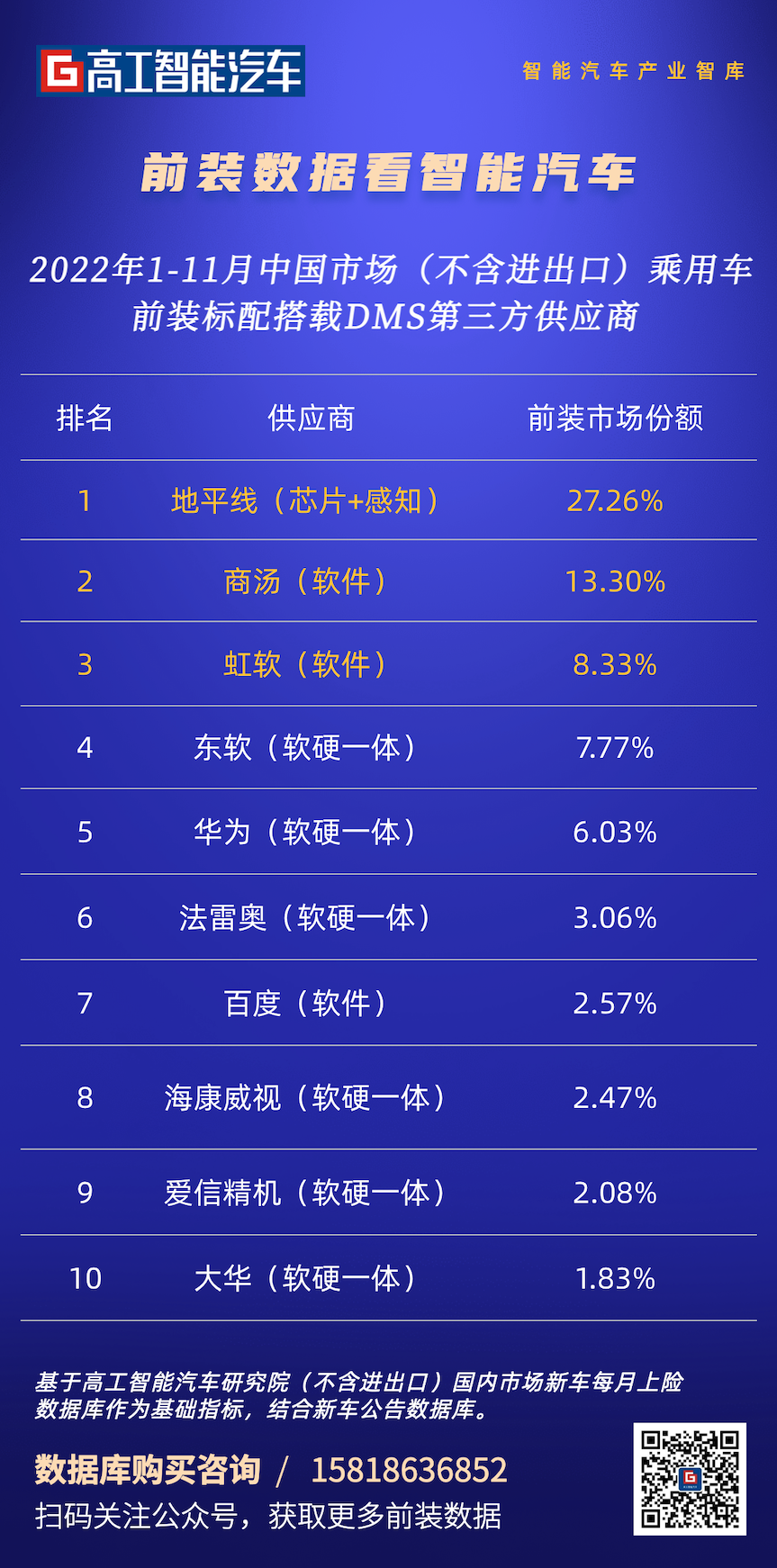
(图片来源:高工智能汽车)
尽管如此,在一年前的《2021 年智能座舱橙皮书》中,我们对于当时的 DMS/OMS 功能给出了一个并不算积极的评价:「麻烦制造机」。
这是因为在此前的座舱评测中,由于 DMS/OMS 在疲劳监测、分心预警、烟雾预警等场景下的误触发、误提醒,的确带来麻烦,让彼时的我们实在无法给出更高的评价。去年年中,小眼睛被系统判定为「开车睡觉」的乌龙事件,也让更多人意识到 DMS/OMS 功能面临的问题:人物生理特征的差异、动作习惯的差异,甚至需求的差异,决定了 DMS/OMS 在实际应用层面需要解决的问题很多。

- 一方面,需要梳理出常见功能场景,通过对场景的判断来过滤可能出现的误报。
- 另一方面,需要对技术标准设置合理、科学的指标。一个人是否处于疲劳状态?处于怎样的疲劳状态?这并不是简单的「Yes or No」的问题,因此,单一、机械化地设定触发阈值,难免出现误触发、误提醒的情况。如何将触发精细化、精准化,是提升 DMS/OMS 性能的关键。
不同等级下生理对于外界刺激的反应、不同时间间隔预警的效果等等,这些差异都能让 DMS/OMS 提供更精准、细致化的服务。

当然,DMS/OMS 本身存在的意义,是为用户带来安全、高效、便捷的服务,在能力提升的同时,区分出哪些是用户真正需要的服务,哪些是不必要的打扰;以及避免座舱内摄像头给用户造成的隐私恐惧,依然是这项功能进化之路上需要解决的问题。
多模态交互:多维度信息的融合,让交互更类人
看着窗户时说「大一点」,车窗能自动打开;眼睛盯着空调时说同样的话,指令就变成了空调开大一点;视线锁定窗外环境,然后说「我想知道这栋楼的用途」,智能助手会自动帮你查询并告知你结果…..

这是以往我们在概念车中看到的场景,利用座舱内语音、视觉、手势识别等多种交互方式融合而成的多模态交互技术,满足了大家对于未来科技感的想象。
在过去几年的智能座舱中,我们已经能看到除了物理按键、旋钮、触控等传统交互形式外,语音交互、手势交互、面部识别等多种交互方式并存的情况,并且已经成为行业主流。
不过相比于以往多种交互方式「单打独斗」、各自为战的情况,多模态交互的本质,在于将不同交互形式间联动起来,通过不同交互形式下多维度信息对于感知能力的互补,让系统能够以更接近自然人的状态去理解、执行人的意图,甚至能够猜测出人未说出口的意图。
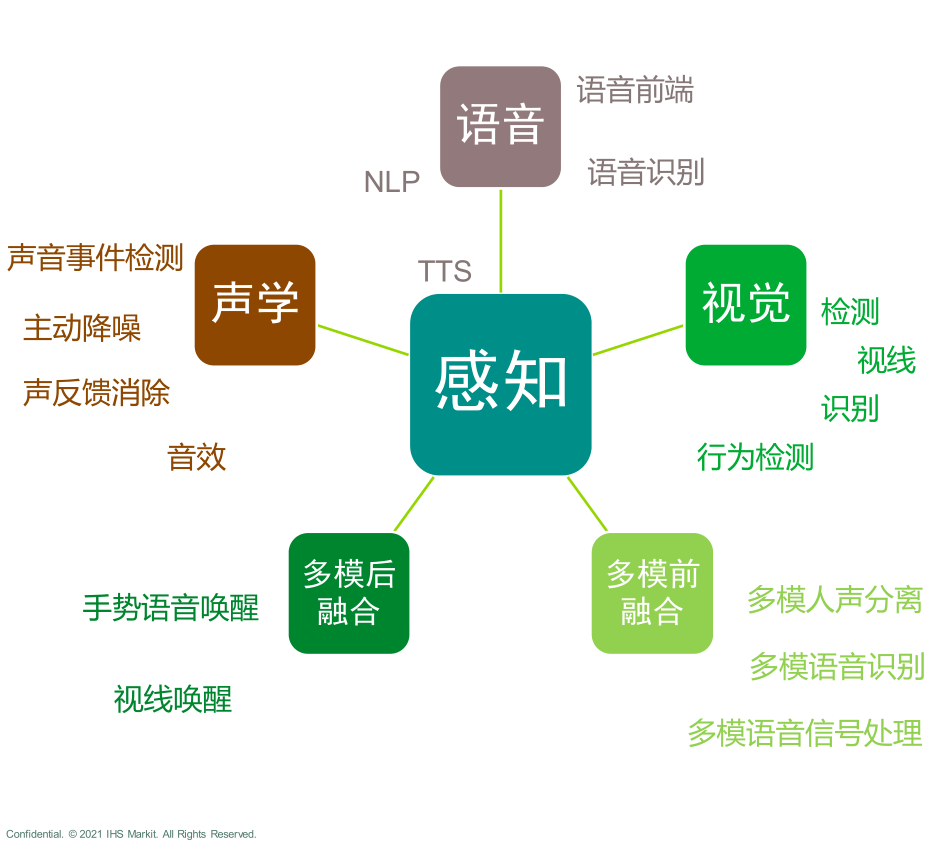
在过去一年中,我们已经能看到这种多模态交互尝试的初级形态。
比如在理想 L9 中,采用了 3D Tof + 语音交互融合的方式,手指向遮阳帘,同时说「打开这个」,遮阳帘可以自动打开。对于一个按键就能打开遮阳帘的操作,这种场景似乎并没有太多的吸引力,但这背后是语音与手势交互融合的能力,这种能力为座舱交互创造了更多的可能性,比如在提升交互准确率方面。

在极狐阿尔法 S HI 版的座舱内,语音识别与唇动识别结合到一起,通过视觉+语音的多模态融合,能够在嘈杂、密集的座舱环境下提升语音识别的准确率;采用类似的视觉+语音融合方案来提升识别准确率的,还有基于地平线征程 2、征程 3 打造的座舱方案 Horizon Halo,通过视觉、语音等多种传感器数据融合,来实现主动交互。

为了达到这个效果,对于语音交互技术架构和语音基础能力的优化是必不可少的;而为了进一步降低误唤醒率,提高识别率,引入视觉感知,将语音与视觉感知、手势识别融合,能为系统提供更多的信息冗余。
采用了 Halo 3.0 方案的奇瑞瑞虎 8 PRO 作为首款全场景多模交互方案的车型,在全时免唤醒功能上就采用了多模态交互技术。

要处理如此海量的数据,需要提供足够的算力、尽可能降低延时的边缘计算能力、对模型不断优化的 AI 技术。这就需要,类似地平线这样的供应商,提供由芯片+算法+工具链构成的一整套解决方案,以及对软硬件联合调优的能力。
相应地,融合后得到的效果更加精准,在高噪声场景下,多模态语音交互的错误率相对降低了 50%,来保证在极限工况下从不可用到可用的提升;特别是针对意图模糊的指令时,给出的反馈更接近自然人的反应。
当然,与 DMS/OMS 类似, 多模态交互存在对意义并不是为了营造科幻感。我们常常在一些智能座舱中看到「为了设计」而出现的设计,在多模态交互的尝试中也不例外。把一键操作、一句话操作拆分成需要调动了用户的语音+手势+肢体动作+表情的多模态交互,并没有为用户的任务量做减法,反而做了加法,最终只能沦为好奇心驱使下的昙花一现,甚至为多模态交互这项技术本身在用户群体带来负面影响。
相应地,只有能够被用户真正需要、能够满足刚需的多模态交互,才会被用户尝试、接受、信任,最终融入智能座舱整体。
总结:座舱交互的未来
未来座舱内的交互会是什么样子?一千人心中可能有一千个答案。不过人与车、环境的关系不变,座舱交互系统减轻人类在驾驶时的信息处理量、逐渐适应人的趋势不变。毕竟「懒」是推动科技进步的第一原动力。
如今我们已经能看到座舱交互能更好地理解用户发出的指令,借助多维感知系统感知到的座舱内环境、状态,综合给出判断; 未来,在此基础上,还会加上座舱外的环境,整车行驶状态,甚至系统对于过往用户状态和所发生行为的「记忆」,根据更多维度信息的融合,对用户的意图做出判断,甚至给出主动无感的服务。
当然这背后需要一系列技能来支撑:更强大的 AI 算力、更高性能的感知硬件、深度神经网络对于算法的优化、模型的迭代优化来处理边界问题,硬件规格的提升,甚至车内车外信息的联动,能够让多模态交互融合更多维度的感知信息……
它们共同让座舱交互逐渐走向真实的类人智能。