
先来一段走心的话
在正文开始之前,我想先要对 Mobileye 公司及其创始人兼 CTO Shashua 博士表示感谢。对 GeekCar 来说,Shashua 每年 CES 期间的发布会演讲一定是整个 CES 当中,我们收获最大的一个小时。从 GeekCar 最早在国内体验 Mobileye 的后装产品开始,这家公司的一系列动作帮助我们加深了对 ADAS 乃至整个自动驾驶行业的了解。或许他们这十几年来对技术的追求与坚持,正是我们所倡导的极客精神。
走心的话说完,下面就该是硬货了。在今年 CES 的演讲上,Shashua 博士再次给我们上了一堂自动驾驶课。这次他除了讲了一些 Mobileye 的技术进展之外,还着重讲了一下自动驾驶行业发展背后的合作伙伴关系以及运作逻辑。
自动驾驶的三个部分
首先,Shashua 博士将自动驾驶分为了三个主要组成部分:Sensing, Mapping, Driving Policy
- Sensing:指车辆所搭载的一切感知设备,包括摄像头,激光雷达,毫米波雷达等等。所有这些传感器所收集到的信息,都将被传输到高性能电脑当中并加以分析,从而帮助车辆了解其所处的周边环境。
- Mapping:指高精度地图,其意义在于帮助车辆在整个路径规划中精确定位。由于自动驾驶所要求的定位精度极高(10CM),GPS 系统已完全无法满足,且完全自动驾驶需要高精度地图覆盖尽可能多的地域并可以做到实时更新。所以,地图数据的收集与扩展就变得尤为重要。
- Driving Policy:指驾驶逻辑或策略,此概念来源于机器人学,具体是指计算机在获得了周边环境的感知信息之后,如何对其做出应对。在驾驶环境中就是如何能够让计算机像人一样在面对不同路况时能够做出相应的判断。目前大热的人工智能与深度学习也是为了要更好地解决这个问题。
 在这三个部分当中,Mobileye 目前都已经有所涉及。传感器方面,Mobileye 的 EyeQ 系统已经是摄像头领域的视觉处理标杆。截止目前,EyeQ 芯片的出货量已经达到了 1,500 万。
在这三个部分当中,Mobileye 目前都已经有所涉及。传感器方面,Mobileye 的 EyeQ 系统已经是摄像头领域的视觉处理标杆。截止目前,EyeQ 芯片的出货量已经达到了 1,500 万。
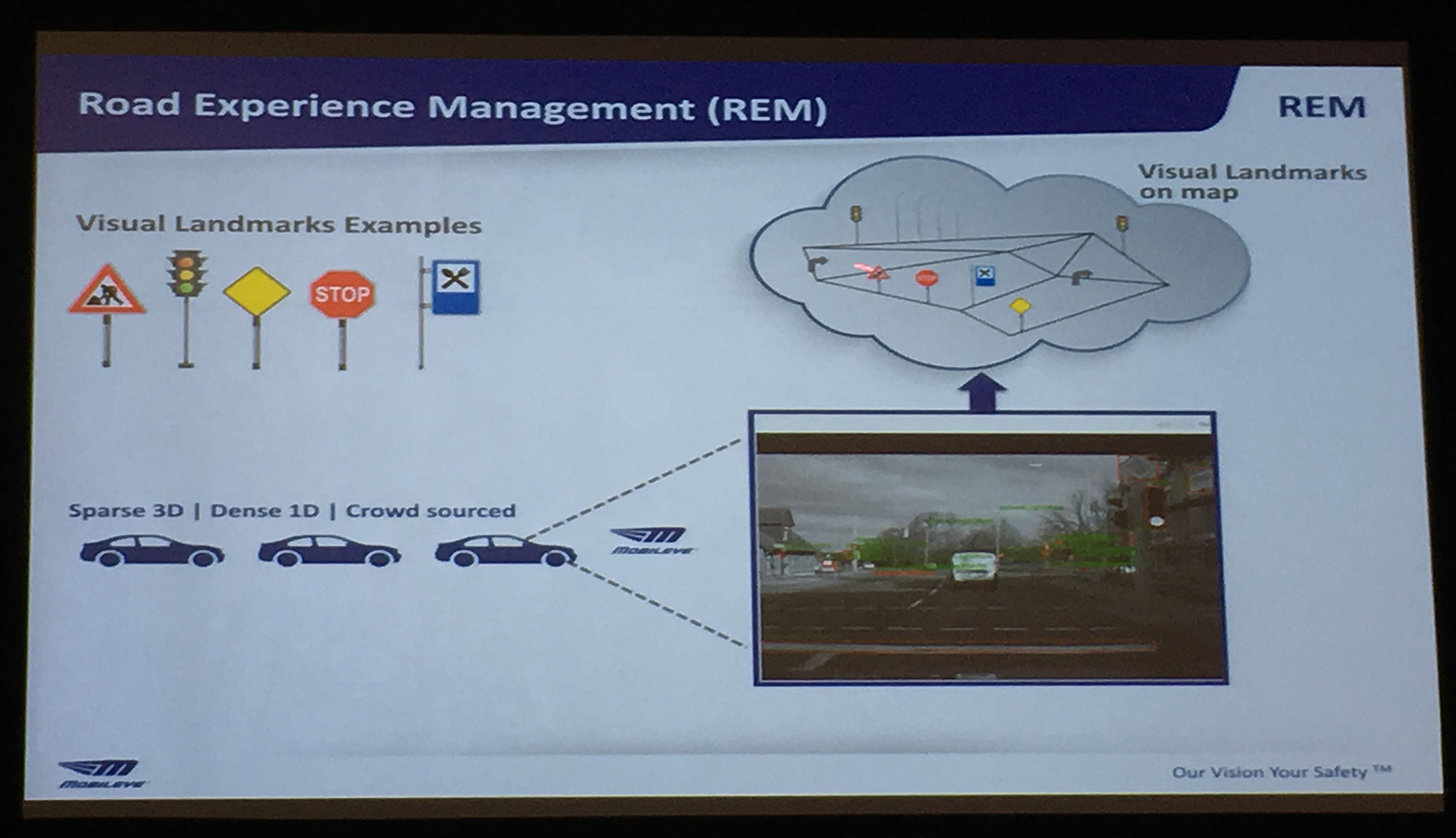
在地图方面,去年 CES 上,Mobileye 发布了其基于摄像头的地图定位技术 REM(Road Experience Management)——通过摄像头捕捉路面上的标识以辅助定位。由于目前大部分车辆都已经配备了前置摄像头,因此 REM 可以利用这些现有的摄像头辅助定位。更方便的是,REM 还可以通过这些车辆前置摄像头来获取更多全新的地图信息,并通过上传云端持续对地图数据库做出更新。
由于摄像头所捕捉到的地图数据为 2D,数据尺寸较 3D 高精度地图要小了很多(一般只有 10KB/KM),因此更利于向云端的传输。这就使得高精度地图的收集与普及变得更加便宜高效。在今年德尔福的自动驾驶演示车上,REM 技术也得到了应用,具体请查看我们之前的体验文章。到 2018 年前,REM 技术将开始陆续通过整合到现有的 EyeQ 芯片当中,届时将会有两百万上路车辆搭载 REM 技术,共同捕捉新的地图数据。


不过在这里,需要特别引入一个「冗余」(Redundancy)的概念:目前对于主机厂和 Tier 1 来说,任何自动驾驶的感知与定位功能都不能够由单一传感器或者技术来完成,因为任何传感器都会有自己的局限性。当某一个传感器因为天气或者光线等特殊原因无法良好工作时,需要有其他的传感器或者备选方案来保证车辆行驶的安全。
因此尽管 REM 的技术有着成本低,普及容易,数据尺寸小等优点,在主机厂的实际产品中,它也不可能完全独揽定位的任务。出于「冗余」的考虑,激光雷达和 3D 高精度地图还是会被引入到解决方案当中,与 REM 共同配合完成定位。在之前我与 Shashua 博士的交谈当中,他自己也提到了这一点。
可以看出,合作才是推动地图与定位技术发展的关键。于是,Mobileye 也开始和其他图商走到了一起:
- Here:将 REM 算法整合到 Here 的 HD Live Map 系统当中,帮助 Here 完善并丰富其高精度地图数据。
- Zenrin:共同组建覆盖全日本高速公路的高精度地图数据,在 2018 年之前与亚洲 OEM 合作完成 L3 级自动驾驶的研发。
Mobileye 在地图领域内的最终目标,是联合各大车厂、图商一起构建一个覆盖全球的高精度地图体系。与和单一整车厂的一般合作不同,这个体系需要多个整车厂、供应商、图商组成共同的联盟才能够达成。目前,Mobileye 正在和各方沟通组建世界地图的具体细节(包括技术,商业,数据归属等等层面)。
Shashua 博士认为,这个体系一旦达成,将会成为自动驾驶行业发展的转折点,因为这样的联盟能够避免竞争,最大化发挥资源及数据整合的优势。

 Driving Policy:自动驾驶面临的最大挑战
Driving Policy:自动驾驶面临的最大挑战
我们日常的驾驶行为看似简单,实则不然,它是由多方控制者(Multi-agent)相互感应相互判断所产生的结果。当车辆对周边的驾驶环境做出感知和反应时,周边环境也会对车辆的行为产生相应的判断与反应。比如,我们在日常开车遇到行人过马路时,经常会遇到互相避让,最后导致双方都无法高效通过的情况。面对这样的问题时,目前的自动驾驶策略是极其保守的(比如选择减速,避让甚至是停车等等)。
这是出于安全的考虑,因为社会舆论是很难接受自动驾驶车辆在行驶过程中出现很多事故的(虽然绝大部分事故还是人为原因造成)。但在实际路面上只采用这种保守的驾驶策略却又很难融入到现有的驾驶环境当中,如果不解决这个问题的话,自动驾驶车辆将无法与其它人为控制的出行方式并存。如何能够让机器像人一样在不同的驾驶策略之间做出相应的调整,同时又能够确保安全,是目前行业所面临的巨大挑战。
为了演示这个挑战的复杂程度,Shashua 博士选取了一种双车道并线(Double lane Merge)的场景,请参看下面的视频:
在视频演示中,Shashua 博士对人为驾驶策略的判断给出了一个非常经典的定义:「在驾驶行为中,我们人类对驾驶策略的判断并不是来自于与其他驾驶者之间的交谈,而是来自于我们的行为,我们的驾驶行为直接表现着我们的意图,例如哪些车我乐意让它并线,哪些车我就不乐意让它并线。」
用这个定义来形容全球司机都盛行的路怒症简直是在合适不过了。而这种驾驶行为所主导的驾驶策略,是机器非常难以模仿的。目前绝大部分上路的自动驾驶测试车辆都是按照严格的驾驶规则与保守的逻辑做出判断,一旦在面对这样复杂、规则不明确且不确定性很强的决策场景时,机器只能选择让人类驾驶者介入。在博士看来,这才是目前自动驾驶发展的最大阻碍。
目前行业中,能解决这个问题的方法是机器学习(Machine Learning),因为它可以通过观察和分析不同的数据来自行生成并调整决策逻辑。之前在围棋比赛中击败各路人类高手的人工智能 AlphaGo 正是通过机器学习当中的深度学习分支来学习下围棋的。
这其中有一个很重要的原则:机器学习是通过分析大量的数据来提升自己的表现,所以面对驾驶场景中,一些罕见的路况环境(数据不充足甚至是没有),机器学习将无法获得足够的学习素材以产生良好的判断。这也是为什么机器学习主导下的自动驾驶需要很长时间的数据积累。
不过,Shashua 在对机器学习提出了更深一层的解读:他认为,目前被大部分公司所宣传的机器学习技术更多的是对车辆当下所处场景的感知与反应,因此这种技术应该被称为「深度监督式学习」(Deep Supervised Learning)。而获取更好的驾驶策略需要的是对未来场景的提前预判,因此其所需要的技术在机器人学中应当叫做「强化学习」(Reinforcement Learning)

这两种技术之间的主要区别来自于对待数据的方式,具体在于:
1. Deep Supervised Learning:这种技术适用于机器做出的行为 不会对 周边环境产生影响的领域。所以训练这种技术所使用的数据是可以被提前搜集的。只要周边环境与规则没有改变,我们就可以通过改变现有数据当中的其他变量来模拟出多种不同的情况用来让机器学习。
举国际象棋的例子,对于任何一场棋局来说,对弈双方所处的环境与规则都是固定不变的(都是以赢得比赛为最终目的),那么只要在现有数据中改变任何一方的任意一个落子行为,都可以相应的模拟出一套新的可用数据,而不用再去真实的对弈场景中重新收集数据。在看国际象棋比赛时,解说员能够在复盘时,从双方任意落子步骤切入,并做出调整,然后再快速还原一个全新的棋局。这正是对现有数据加以重复利用的结果。
2. Reinforcement Learning:与上一条技术相对应的,Reinforcement Learning 适用于机器所做出的行为 会对 周边环境产生影响的领域。自动驾驶就是一个很好的例子,在这个场景下,机器所做出的一系列驾驶行为都会对周边的环境以及其他驾驶者的判断规则产生影响。这就需要系统在每一次改变自己的驾驶策略后,都要重新回到实际驾驶场景当中再从头收集一遍数据。
因为在现有数据当中,机器是无法完全模拟出周围驾驶者对其新的驾驶策略所做出的反应的。试想一下,在并线场景中,如果机器将自己的驾驶策略由保守变为激进,那么周边的驾驶者既有可能采取更加保守的应对策略,也有可能采取更加激进的应对策略,还有可能什么应对策略也不用,而这其中的每一种情况,最终都会产生完全不同的路况结果。所以说,面对这种复杂的不确定性,就需要大量反复的重新采集数据,在面临罕见路况时,数据收集将变得难上加难。这也就大大拖慢了「增强学习」的学习效率。

为了解决 Reinforcement Learning 的数据来源与采集效率问题,Mobileye 正在研究一套新的方法论,并在上个月发布了一篇相关的论文。在演讲过程中,Shashua 博士并没有具体展开这套方法论,而是通过另一个双车道并线的模拟视频来演示了一下这套方法论所达到的效果:
在这个模拟场景中,Mobileye 植入了多个拥有随机驾驶决策的车辆,这其中,红色的车辆最终要并到右侧车道,而白色的车辆要并到左侧的车道。所有的车辆都将按照 Mobileye 的算法进行学习。Shuashua 介绍,目前这个模拟场景的并线成功率已经达到了 99.8%,且已经达到了零事故率。
行业联合:一个美好的理想
再高效的算法也还是需要大量的数据来支撑的。因此与高精度地图相似,驾驶策略的优化也需要行业内行驶数据的共享。在这里,Shashua 博士再次强调了行业内的联盟以及标准化的重要性。从 Mobileye 与宝马、英特尔的联合,再到 Mobileye 与德尔福的合作,Shashua 博士一直在尝试着推广自己的这套「大爱式」的联合思想。
但是,行业内的其它企业,尤其是主机厂会买他的帐吗?在演讲后的提问环节,有人提出了这样的问题。Shashua 的回答也是十分坦诚:「现在我们在和主机厂谈行业联合以及数据共享时确实感觉困难重重,但是我们还是会继续努力的。」 而在我之前和 Shashua 的交谈中,他告诉我 Mobileye 是不介意与合作伙伴共享数据的。
如果仅仅从自动驾驶技术本身的发展角度来看,不管是地图还是算法,数据共享绝对都会是一个大大的利好。但是,毕竟大家还是在汽车行业做生意的,竞争意识在所难免。Mobileye 对行业联合的呼吁背后也隐藏着希望定义行业算法标准的野心。
目前业内的各种合作,倒不如说是在拉帮结派,每个公司还是在全力的宣传着自己的优势。想要让所有人都因为自动驾驶而团结在一起,这或许只能是一个美好的理想。
原创声明: 本文为 GeekCar 原创作品,欢迎转载。转载时请在文章开头注明作者和「来源自 GeekCar」,并附上原文链接,不得修改原文内容,谢谢合作!
欢迎关注 GeekCar 微信公众号: GeekCar 极客汽车(微信号:GeekCar)&极市(微信号:geeket)。